AMD has announced the Radeon RX 9070 at $549 and the RX 9070 XT at $599, both of which ship on March 6. The AMD RDNA 4 architecture and Radeon RX 9000-series GPUs were partially revealed at CES 2025, except they weren’t part of AMD’s keynote. Very little was known (officially) other than the names of the first two graphics cards for the family. That changes today, with AMD detailing many of the architectural upgrades, specifications, and more, during a video presentation. These will go up against the Nvidia Blackwell RTX 50-series GPUs and the Intel Battlemage Arc B-series GPUs and will likely join the ranks of the best graphics cards in the coming days.
Like Nvidia’s RTX 50-series graphics cards, AMD’s RDNA 4 launch seems to have been delayed, though perhaps for different reasons. There were rumors that the cards would be revealed at CES 2025 and launched in January, then February, and finally March. That last is no longer a rumor, with the RX 9070 XT and RX 9070 set to go on sale on March 6 — and in typical fashion, the “MSRP” or base model cards will have reviews go up the day before, followed by the overclocked non-MSRP models on the launch date. Nvidia’s RTX 5070 will likely land right around the same time, just to make things even more exciting.
Image 1 of 44

(Image credit: AMD)


(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)


(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)


(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)
(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)
(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)
(Image credit: AMD)
(Image credit: AMD)
(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)
But if you look at graphics card availability right now, what becomes immediately clear is that virtually everything is sold out or, at the very least, seriously overpriced. AMD has had difficulties with GPU transitions in the past, with the prior generation hanging around for too long and competing with the new parts. This time, it seems to have gone the opposite way, with RX 7000-series GPUs mostly having disappeared from retail shelves in December and January. Only the lower tier RX 7600 and RX 7600 XT are still in stock at MSRP (or close to it).
The result has been dramatically increased demand for everything from mainstream to high-end graphics cards, and Nvidia’s RTX 5090, RTX 5080, and RTX 5070 Ti all sold out almost instantly at launch. Will AMD’s 9070 XT and 9070 fare better? We can hope so, but we suspect there’s so much pent-up demand that even with another two months’ worth of production and supply, it will still be insufficient. Hopefully, things will settle down later this year, but in the near term, we expect inadequate supplies and increased retail prices — and, yes, scalping.
No doubt Nvidia’s record profits driven by AI are a big contributor, and while AMD isn’t selling quite as many data center GPUs, a lot of its wafer allocation from TSMC is likely going to data center CPUs and GPUs as well. Gamers are no longer the top priority for either company, in other words; for the time being, they just get the scraps that fall from the AI table.
But enough sad talk. Let’s check out the specifications for AMD’s RDNA 4 GPUs, talk about architectural updates, and dig into all the other details. We even have pricing information, though as you can guess, that’s worth about as much as the paper this is printed on. We’ll continue updating this article as additional details become available, but for now, here’s everything you need to know about the AMD RDNA 4 and Radeon RX 9000-series GPUs.
RDNA 4 GPU specifications
Here are the known specifications for the RX 9070 series GPUs, along with placeholder information on the RX 9060 series. AMD did share the 9060 name at CES 2025, but no other details have been shared. There are rumors, however, which we’ve used to flesh out the table — these are indicated by question marks in the various cells.
Swipe to scroll horizontally
Graphics Card
RX 9070 XT
RX 9070
RX 9060 XT?
RX 9060?
Architecture
Navi 48
Navi 48
Navi 48?
Navi 44?
Process Technology
TSMC N4P
TSMC N4P
TSMC N4P
TSMC N4P?
Transistors (Billion)
53.9
53.9
53.9
22?
Die size (mm^2)
356.5
356.5
356.5
153?
SMs / CUs / Xe-Cores
64
56
32?
20?
GPU Shaders (ALUs)
4096
3584
2048?
1280?
Tensor / AI Cores
128
112
64?
40?
Ray Tracing Cores
64
56
32?
20?
Boost Clock (MHz)
2970
2520
2790?
2700?
VRAM Speed (Gbps)
20
20
20?
20?
VRAM (GB)
16
16
12?
8?
VRAM Bus Width
256
256
192?
128?
L2 / Infinity Cache
64
64
48?
32?
Render Output Units
128
128
96?
64?
Texture Mapping Units
256
224
128?
80?
TFLOPS FP32 (Boost)
48.7
36.1
22.9?
13.8?
TFLOPS FP16 (FP4/FP8 TFLOPS)
389 (1557)
289 (1156)
183 (731)?
111 (442)?
Bandwidth (GB/s)
640
640
480?
320?
TBP (watts)
304
220
150?
120?
Launch Date
Mar 2025
Mar 2025
Apr–Jun 2025?
Apr–Jun 2025?
Launch Price
$599
$549
$399?
$299?
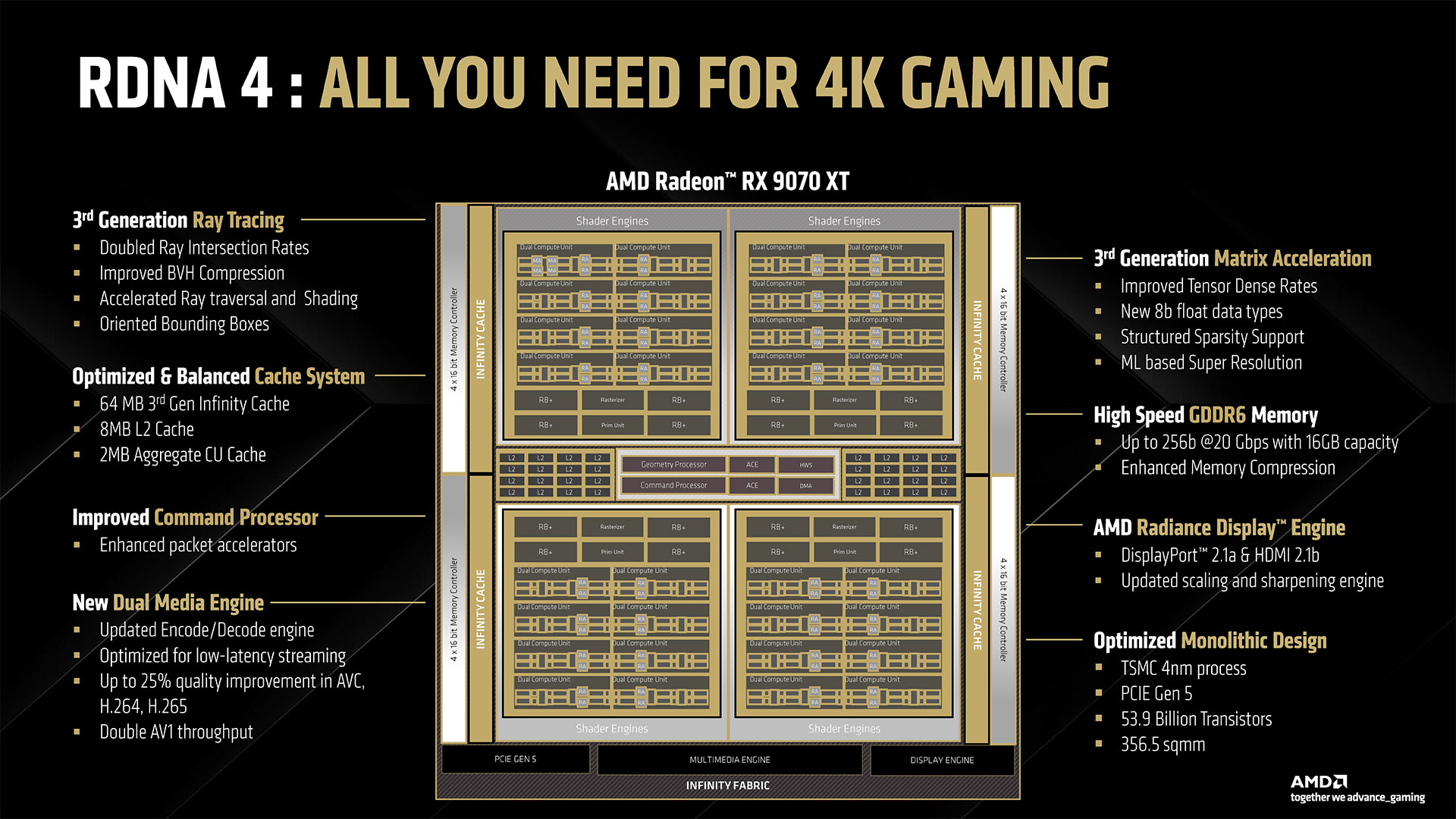
The RX 9070 XT and 9070 columns should be fully accurate. We’re reasonably sure there will be a trimmed-down RX 9060 XT using the same Navi 48 die as the 9070 cards, just with fewer CUs (Compute Units) and memory controllers enabled. Below that, things get murky. The RX 9060 could use a further binned Navi 48, or it could use Navi 44. Most of the details on Navi 44 are questionable at best, but we’ll certainly find out more in the coming months. There might even be RX 9050-class GPUs at some point, but we’ve avoided listing those for the time being. Looking at the RX 9070 XT, it uses a fully enabled Navi 48 die that includes 64 RDNA 4 CUs. Combined with a 2.97 GHz boost clock and a 256-bit memory interface with 20 Gbps GDDR6 VRAM, the other specifications mostly come from straight mathematical calculations. The RX 9070 is mostly the same configuration, just with 56 CUs and a 2.52 GHz boost clock — substantially lower than its bigger sibling, though we’ll have to wait and see what real-world clocks actually look like. Power targets also play a role in the final clock speeds, and where the 9070 XT has a 304W TBP (Total Board Power), the 9070 cuts that all the way down to 220W. That’s probably a big factor in the 450 MHz difference in boost clocks. Raw compute works out to 48.7 TFLOPS FP32 on the 9070 XT and 36.1 TFLOPS on the 9070. On paper, that makes the XT up to 35% faster. In practice, we suspect the two chips will be quite a bit closer and that the actual clocks in most games may only be a couple hundred MHz apart, despite what the specs suggest. AMD has also given the Ray Accelerators and AI Accelerators in the CUs a massive overhaul compared to RDNA 3. For AI, each can do twice as many FP16 operations per cycle and they now support sparse operations. Sparsity can skip up to half of the zero multiply operations to potentially double performance, and it’s a feature Nvidia has supported since its second-generation RTX 30-series GPUs. (AMD has also supported sparse operations on its CDNA family of GPUs for several years.) Moreover, the AI units also support FP8, INT8, BF8, and INT4 operations, with the 8-bit calculations being twice as fast as 16-bit, and 4-bit integers double that again. Put it all together, and you get 389 TFLOPS of sparse FP16 compute and up to 1557 TOPS of sparse INT4 compute. Keep in mind that the previous generation RDNA 3 architecture featured GPUs with up to 96 CUs and a 384-bit memory interface on the RX 7900 XTX, so while RDNA 4 GPUs are faster on a per-CU basis, AMD doesn’t expect the RX 9070 XT to beat the RX 7900 XTX in all workloads.
There’s a lot more going on than the raw specs will tell you. First, let’s cover the pricing and launch date, then move on to the architectural deep dive.
RX 9070 XT and RX 9070 Performance
Image 1 of 6
(Image credit: AMD)
(Image credit: AMD)
(Image credit: AMD)
(Image credit: AMD)
(Image credit: AMD)
(Image credit: AMD)
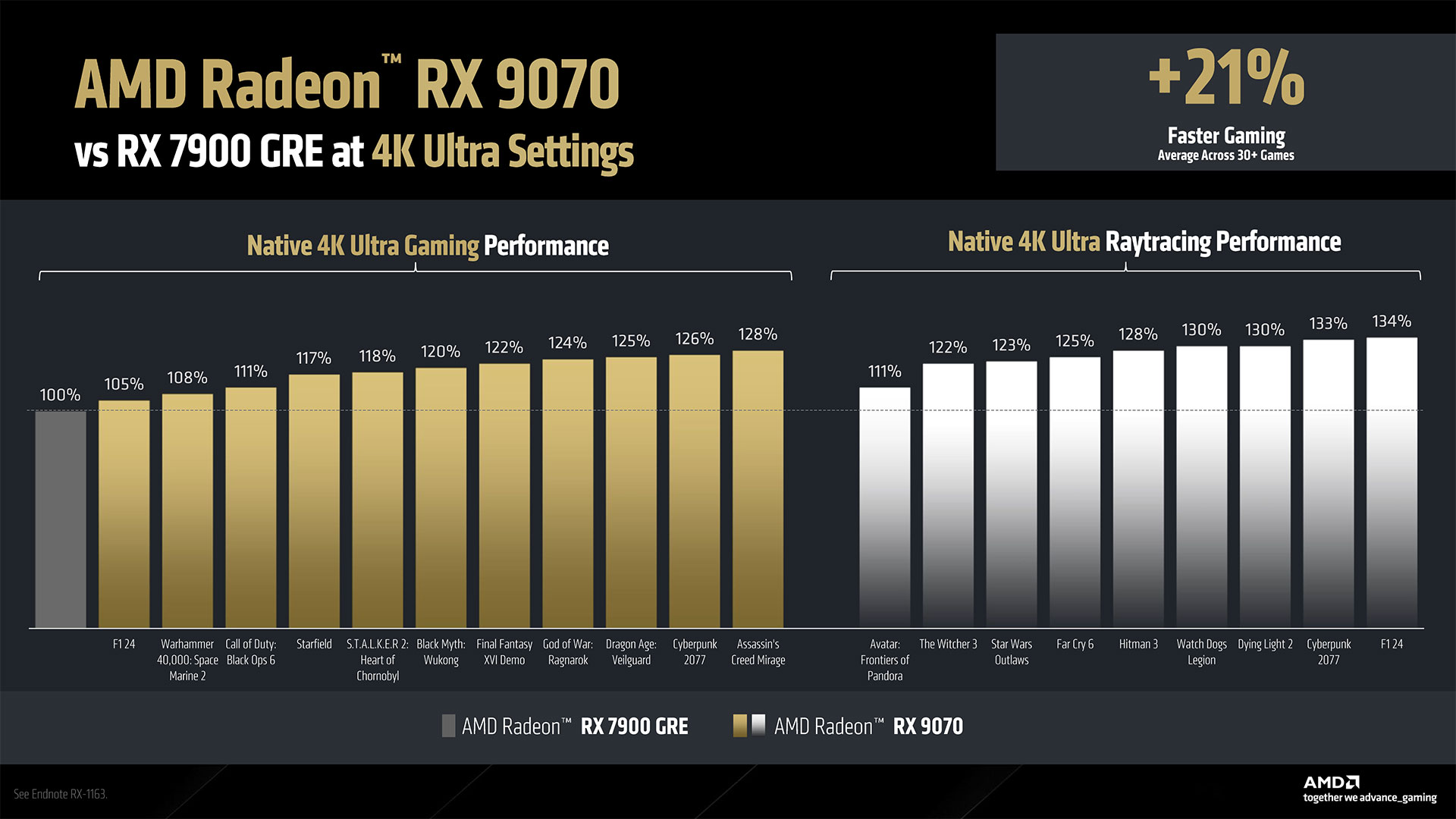
How fast are the RX 9070 XT and RX 9070 graphics cards? We can’t share our own internal benchmarks yet, but AMD provided comparisons against its previous generation RX 7900 GRE. In it’s testing of 11 rasterization games and nine ray tracing games, the 9070 XT was on average 42% faster at 4K and 38% faster at 1440p, while the 9070 was 21% faster at 4K and 20% faster at 1440p. Breaking things down into pure rasterization and pure ray tracing performance, the 9070 XT delivered 37% and 33% improvements in performance at 4K and 1440p in rasterization mode. In ray tracing games, it was 53% and 49% faster on average, again at 4K and 1440p, respectively. The RX 9070 meanwhile provided 18% and 17% higher rasterization performance at 4K and 1440p, while in ray tracing it was 22% and 20% faster on average. These are AMD’s own numbers, so we can’t fully vouch for them, but we can use them to get a reasonable idea of where the new AMD cards might land relative to the RTX 5070 Ti and RTX 4070 Ti Super (both 16GB cards).
In our GPU benchmarks hierarchy, at 4K in our rasterization test suite the RTX 4070 Ti Super beats the 7900 GRE by 13% at 4K and 7% at 1440p. The RTX 5070 Ti on the other hand was 14% faster than the 4070 Ti Super at 4K and 11% faster at 1440p. Taken together, our existing test results indicate the 5070 Ti would be around 29% faster than the 7900 GRE for 4K rasterization and 19% faster at 1440p.
Flip over to ray tracing and our data has the 4070 Ti Super beating the 7900 GRE by 64% at 4K and 60% at 1440p. The new RTX 5070 Ti leads the 4070 Ti Super by 12% at both 4K and 1440p. That would thus put the 5070 Ti potentially 84% and 79% ahead of the 9070 XT. Clear as mud? Let’s put it this way: Our existing data combined with AMD’s data suggests the 9070 XT will beat the 5070 Ti by perhaps 6% at 4K for rasterization and 12% at 1440p. In ray tracing, however, Nvidia would appear to still have the edge and be around 20% faster at 4K and 1440p. We can’t be precise just because there are other factors in play — different testing suites, different platforms, and two levels of extrapolation (because we haven’t tested the 7900 GRE on our new test suite yet), but overall it appears the 9070 XT will land reasonably close to the 5070 Ti in perforamnce.
Doing the same calculations for the vanilla RX 9070, it would be a decent 12 to 17 percent slower than the 9070 XT, which would be about where the RTX 4070 Ti sits in our testing. But we don’t know precisely where the RTX 5070 will land yet, so we can’t really come to any conclusion. With only 12GB of VRAM on the Nvidia 5070, however, it seems more likely that the 9070 will take an overall lead. We’ll find out for certain next week, so stay tuned.
RX 9000-Series Pricing

(Image credit: Shutterstock)
How much will the RX 9000-series GPUs cost? AMD has announced the Radeon RX 9070 will start at $549 and the RX 9070 XT will start at $599, placing them firmly in the “mainstream” segment. Given the current market conditions, however, it probably doesn’t matter what AMD has given as the MSRP. Short-term, certainly, we expect the cards will all sell out and end up costing much more than the MSRP. As we said in the Nvidia Blackwell overview, for dedicated desktop graphics cards, we’re now living in a world where “budget” means around $250–$300, “mainstream” means $400–$700, “high-end” is for GPUs costing $800 to $1,000, and the “enthusiast” segment targets $1,500 or more. AMD is going after the mainstream segment with the 9070 series, and possibly the lower mainstream and upper budget segments with future 9060 series parts. Depending on supply, as well as performance, the RDNA 4 series should be worth the price AMD is asking. More likely is that there simply won’t be enough cards to satisfy the current demand, not for many months. Given the reasonably low-ish prices, don’t be surprised if scalpers and retail markups step in and push the prices up.
It’s basically a repeat of the cryptocurrency GPU mining shortages, only this time it’s caused by AI and demand from that sector may not go away for many years. Let’s hope we’re wrong, but the RTX 50-series launches so far have not been promising.
We listed the March 6, 2025 release date for the RX 9070 cards already, but AMD has also at least partially teased an RX 9060 family of GPUs. Will there be multiple cards or only one? Will there be lower-tier RX 9050 cards as well? The short answer: We don’t know. The nebulous answer: Sometime between April and the end of the year, hopefully sooner than later.
We’ve seen rumored die sizes for Navi 44 that suggest it’s a much smaller chip, like more of a replacement for the current Navi 33 (RX 7600 series). If that’s correct, it may not come out any time soon. There still appear to be plenty of RX 7600 and RX 7600 XT GPUs floating around, and that’s because when those launched there were still a lot of similar performing Navi 23 (RX 6650 XT / RX 6600 XT / RX 6600) cards still available, at lower prices.
The naming scheme from AMD suggests that the RX 9060 will compete with the RTX 5060 family. That would perhaps require a larger chip than what’s indicated. But RX 7600 does technically compete with the RTX 4060, and there’s no RTX 4050 and probably won’t be an RTX 5050. Will AMD be making a “true budget” RDNA 4 chip? Again, rumors suggest that’s at least possible, perhaps even likely. At less than half the size of Navi 48, AMD may try to create a $200~$250 graphics card to go after budget-minded gamers — and OEMs. Certainly it could get a lot more chips per wafer with the rumored 150~160 mm^2 die size.
But if the cards then only sell for $250 or less? That hardly seems worth the effort, not when companies can charge tens of thousands for data center GPUs.
Get Tom’s Hardware’s best news and in-depth reviews, straight to your inbox.
RDNA 4 Core GPU Architecture
Image 1 of 23

(Image credit: AMD)
(Image credit: AMD)
(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)
(Image credit: AMD)

(Image credit: AMD)
(Image credit: AMD)

(Image credit: AMD)
(Image credit: AMD)

(Image credit: AMD)
(Image credit: AMD)

(Image credit: AMD)
(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)
(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)
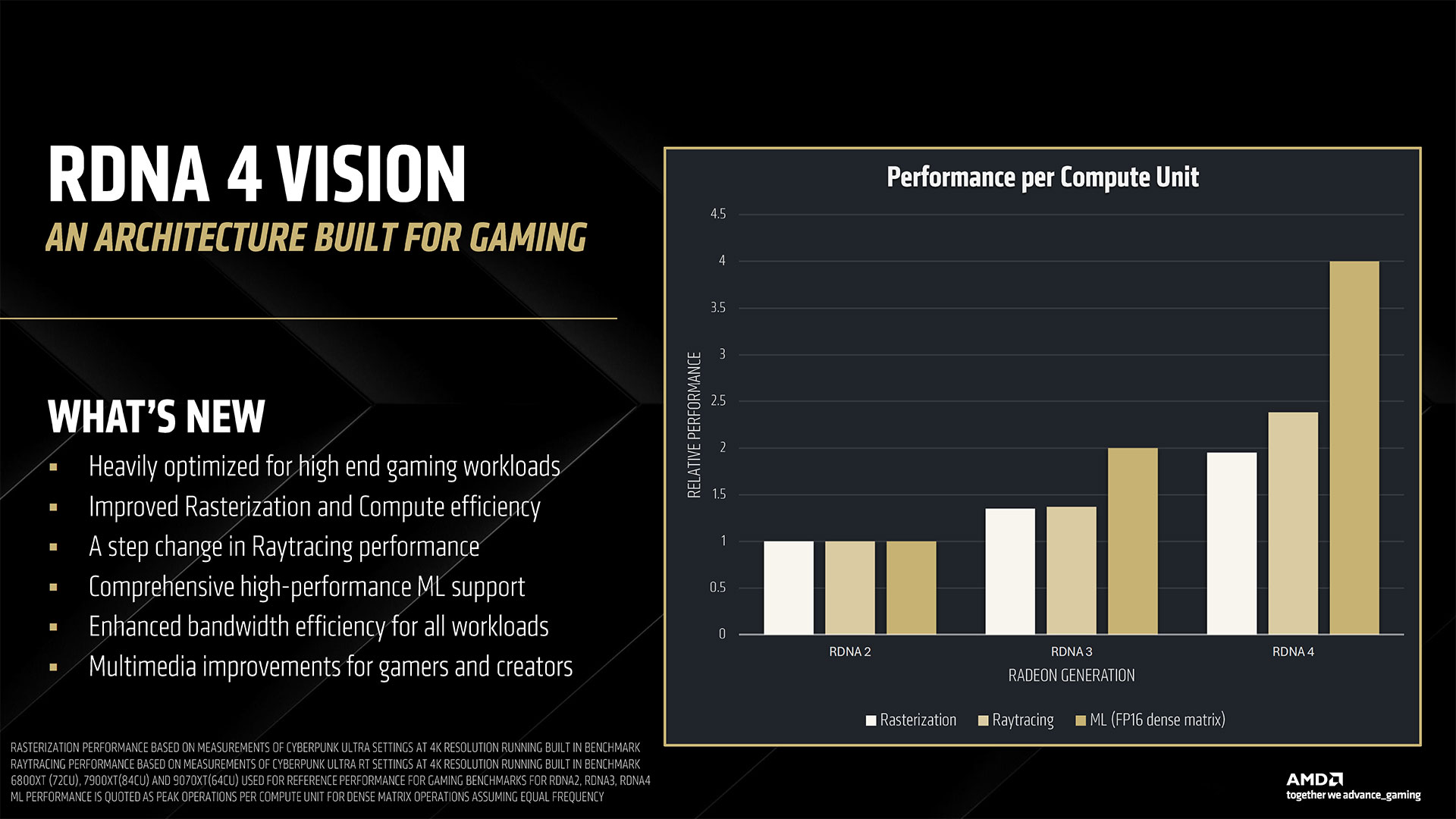
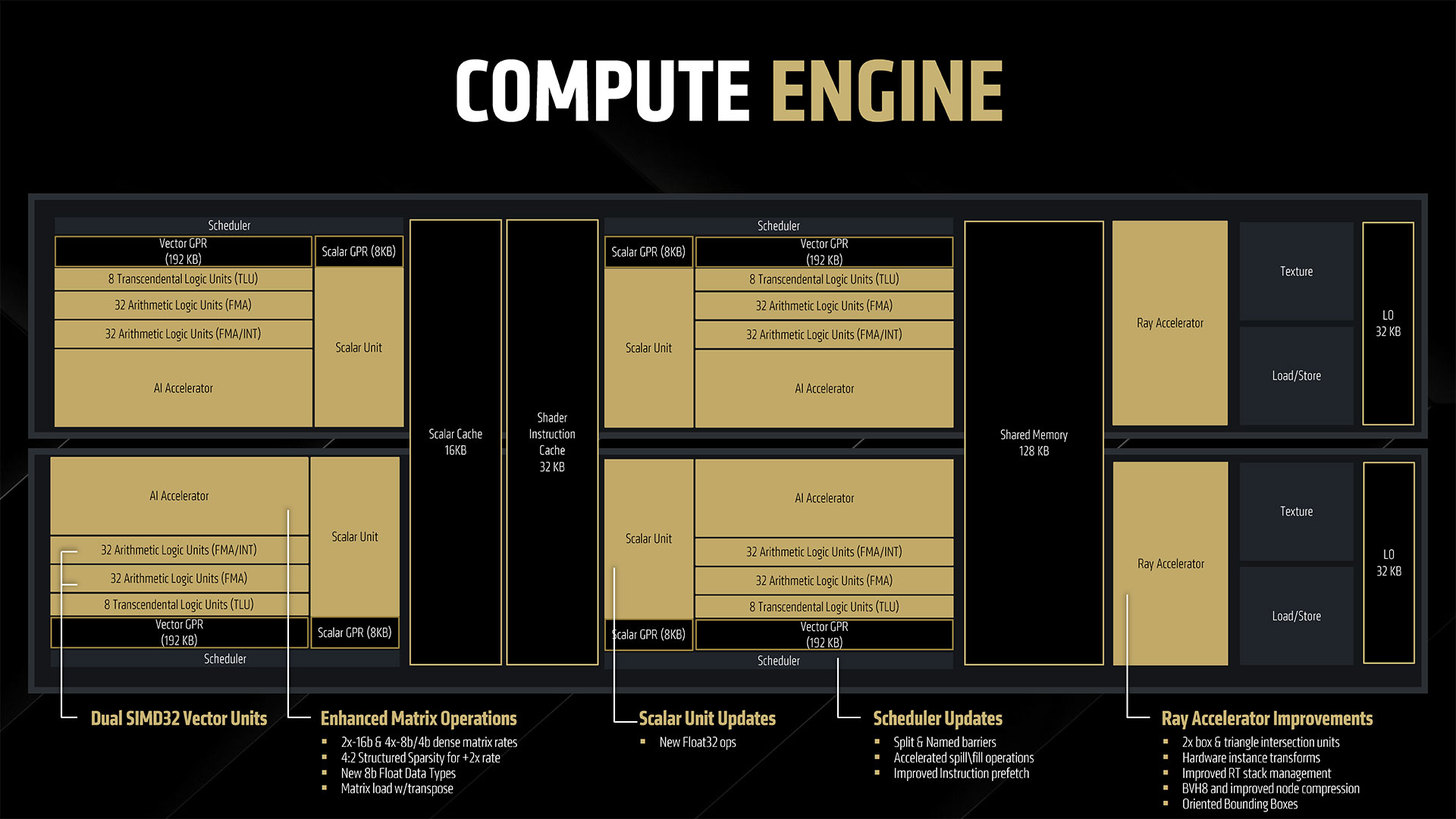
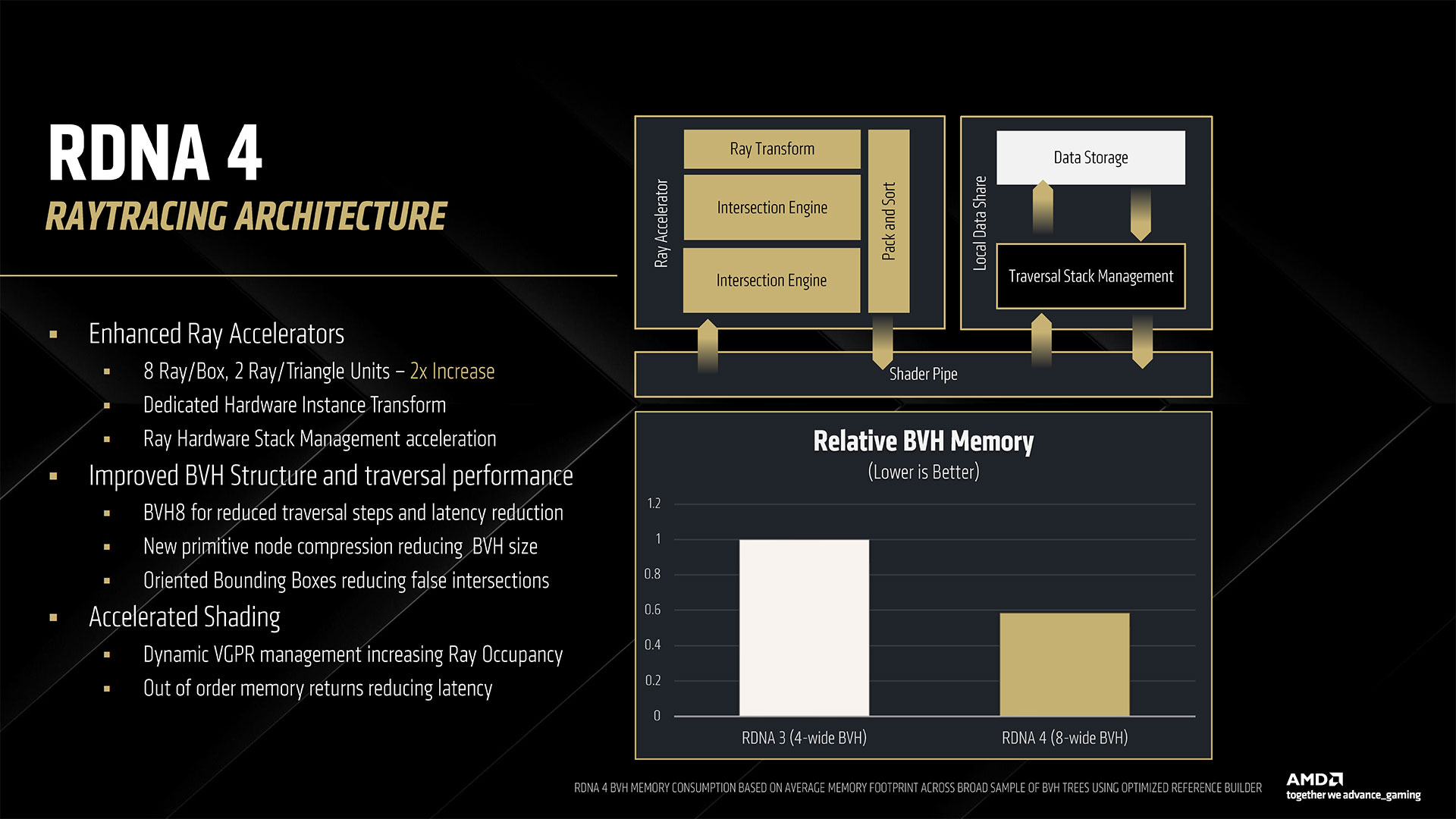
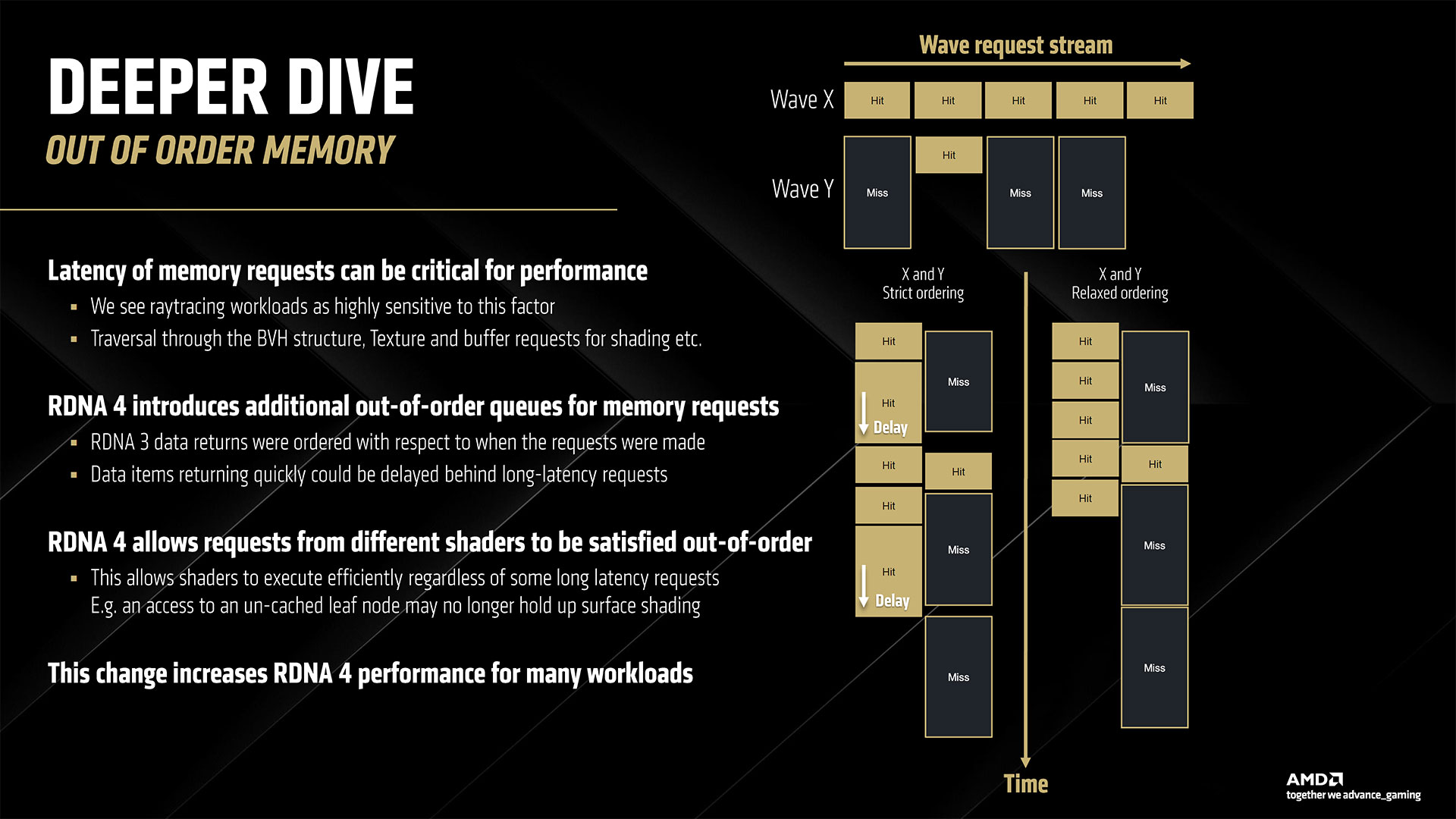
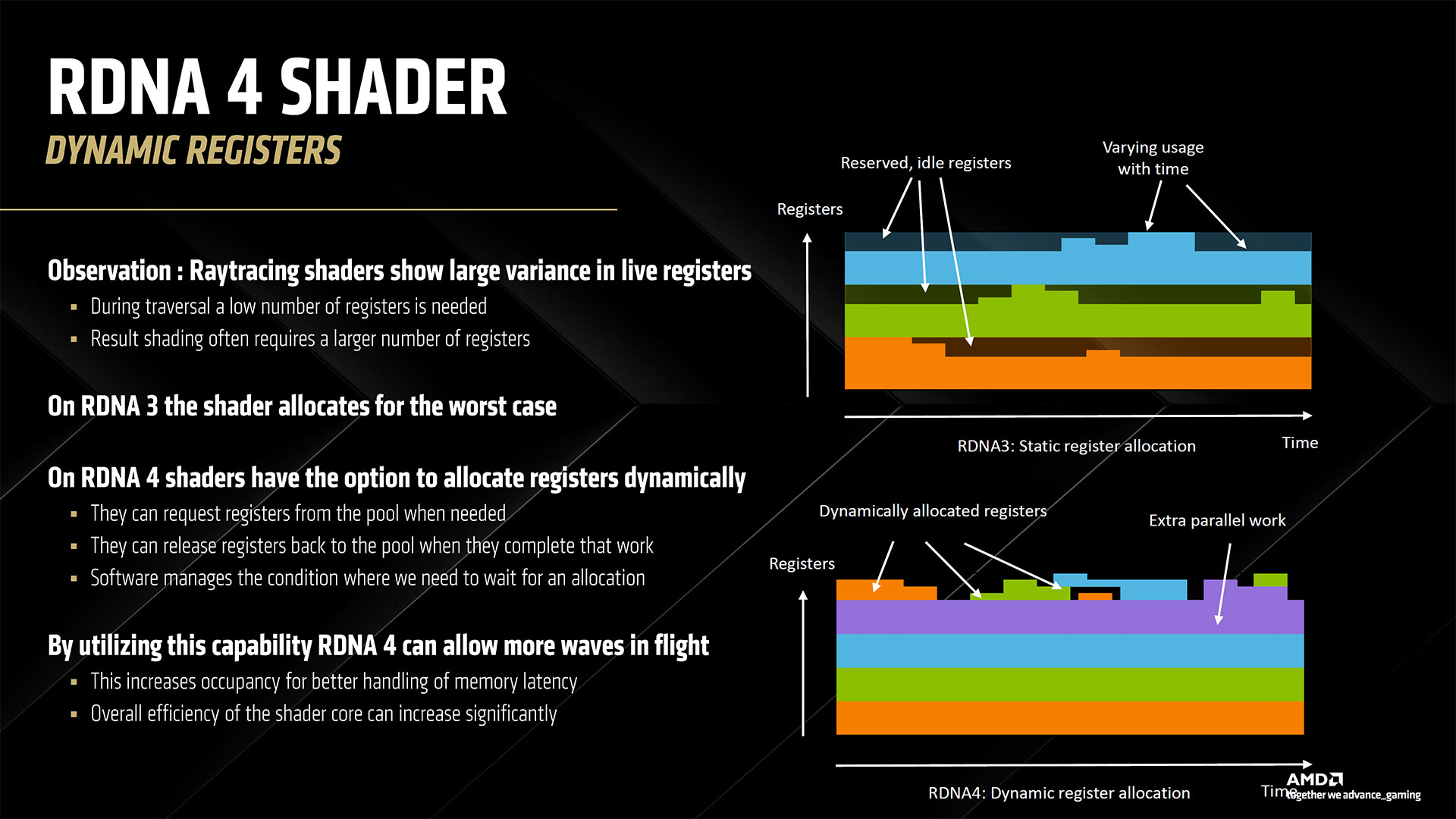
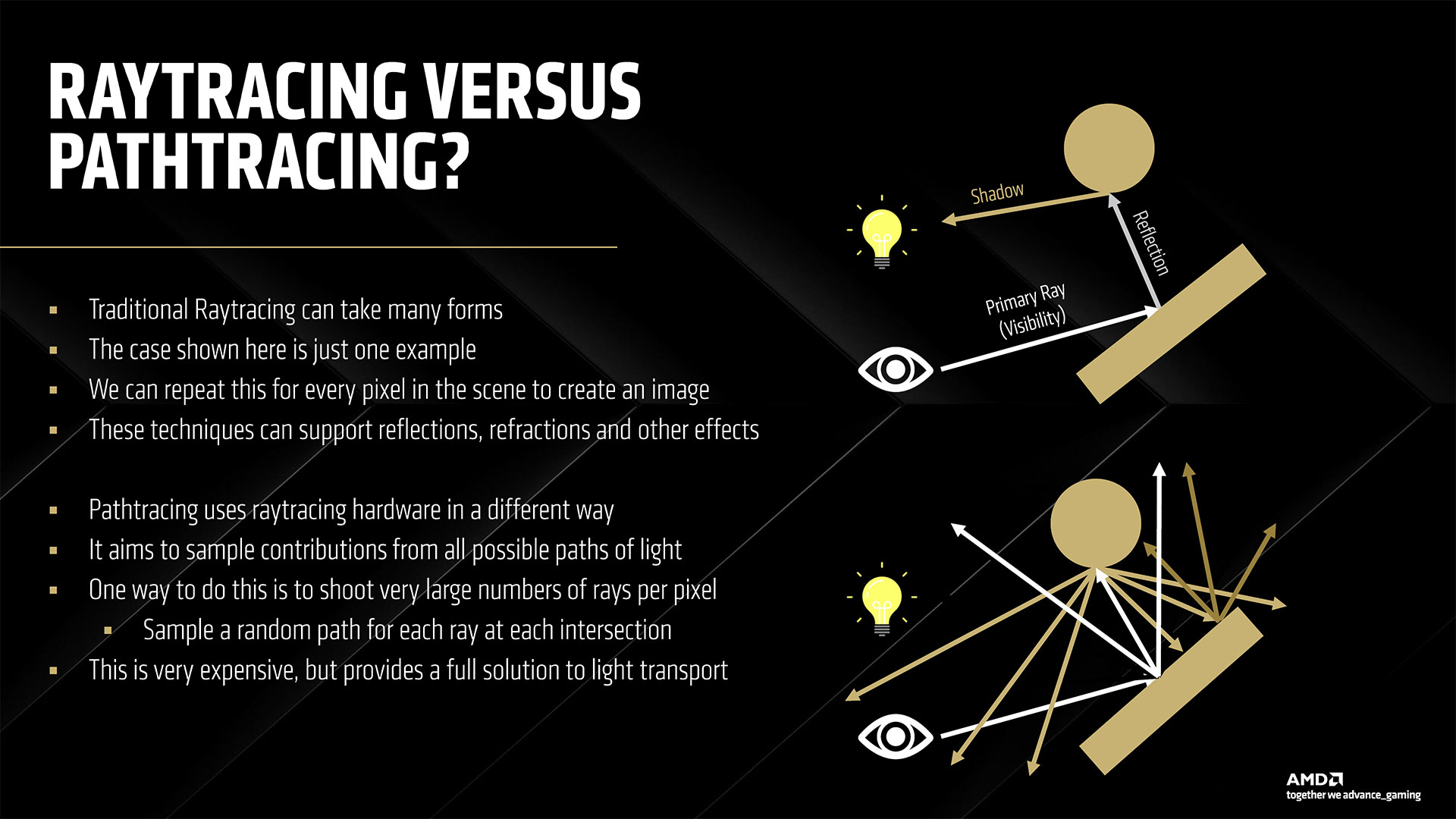
The above slide gallery covers the architectural briefing AMD provided in advance of today’s reveal, including some of the specifications discussed above as well as finer details. AMD worked to refine the underlying architecture to improve per-CU performance in all major workloads: rasterization, ray tracing, and AI. Rasterization performance sees the smallest generational gains, but it’s still about 40% faster than RDNA 3 according to AMD. Ray tracing performance is basically doubled, and AI performance is doubled for dense FP16 compute, with lower precision formats delivering even higher performance. The specific details of the rasterization improvements are a bit nebulous. RDNA 4 supports out of order memory requests, which AMD specifically notes as being helpful for ray tracing, but it can help rasterization tasks as well — we just don’t have any details on how much. The other major change involves dynamic register allocation. RDNA 3 (and earlier) allocated registers for the worst case for shaders. By dynamically allocating extra registers only when needed, AMD provides an example use case where it could have an extra wave in flight. The slides show three waves versus four waves, which would be a 33% increase, but we don’t know if that’s representative of real workloads or just for illustrative purposes. Moving on to ray tracing, this is where AMD spent a significant amount of effort. It doubled the ray/triangle and ray/box intersection rates per RT unit as a start. THen it offers some enhancements including hardware instance transforms (rather than doing a lot of the work via GPU shaders), oriented bounding boxes, an improved BVH (Bounding Volume Hierarchy) structure and traversal, the above-mentioned out of order memory returns, and better ray hardware stack management. Most of the improvements come from the doubling of intersection rates and BVH compression, but the other aspects combine to deliver a solid improvement as well. How does RDNA 4 compare with Nvidia’s latest hardware? That’s not fully clear, but certainly it’s going to do better per CU than what we saw with RDNA 3 and RDNA 2. It likely won’t match Blackwell, but it might be better than Ampere and at least closer to Ada levels of performance. AI, as already noted, sees the biggest changes. Nvidia has been iterating on its AI tensor cores since the RTX 20-series, and even before that the Volta data center GPU had tensor cores. So Nvidia is on its fifth generation of AI matrix cores while AMD is mostly on its second generation — mostly because it looks like AMD took a lot of the work that’s been happening in its CDNA GPUs and brought it over to RDNA 4.
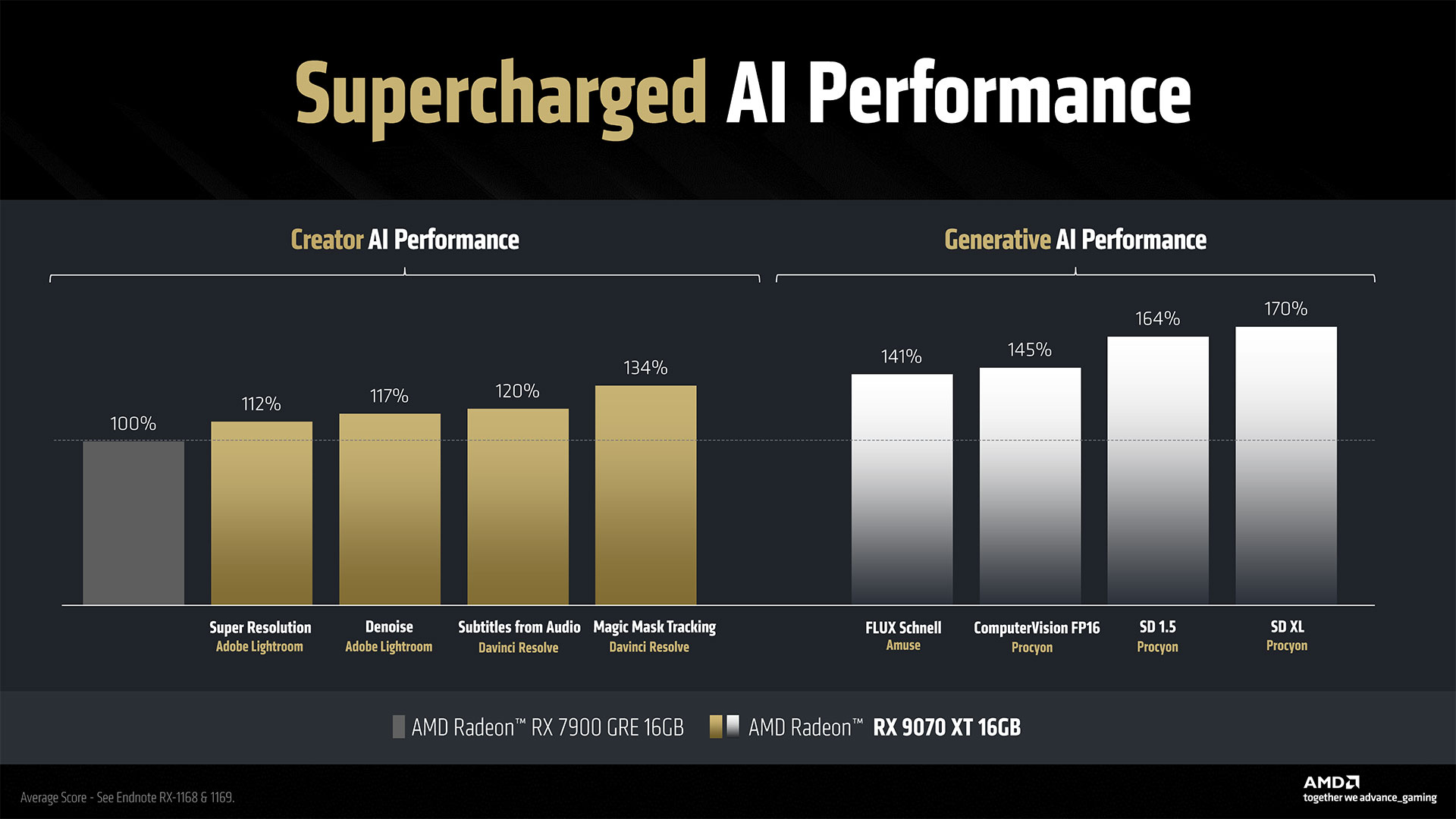
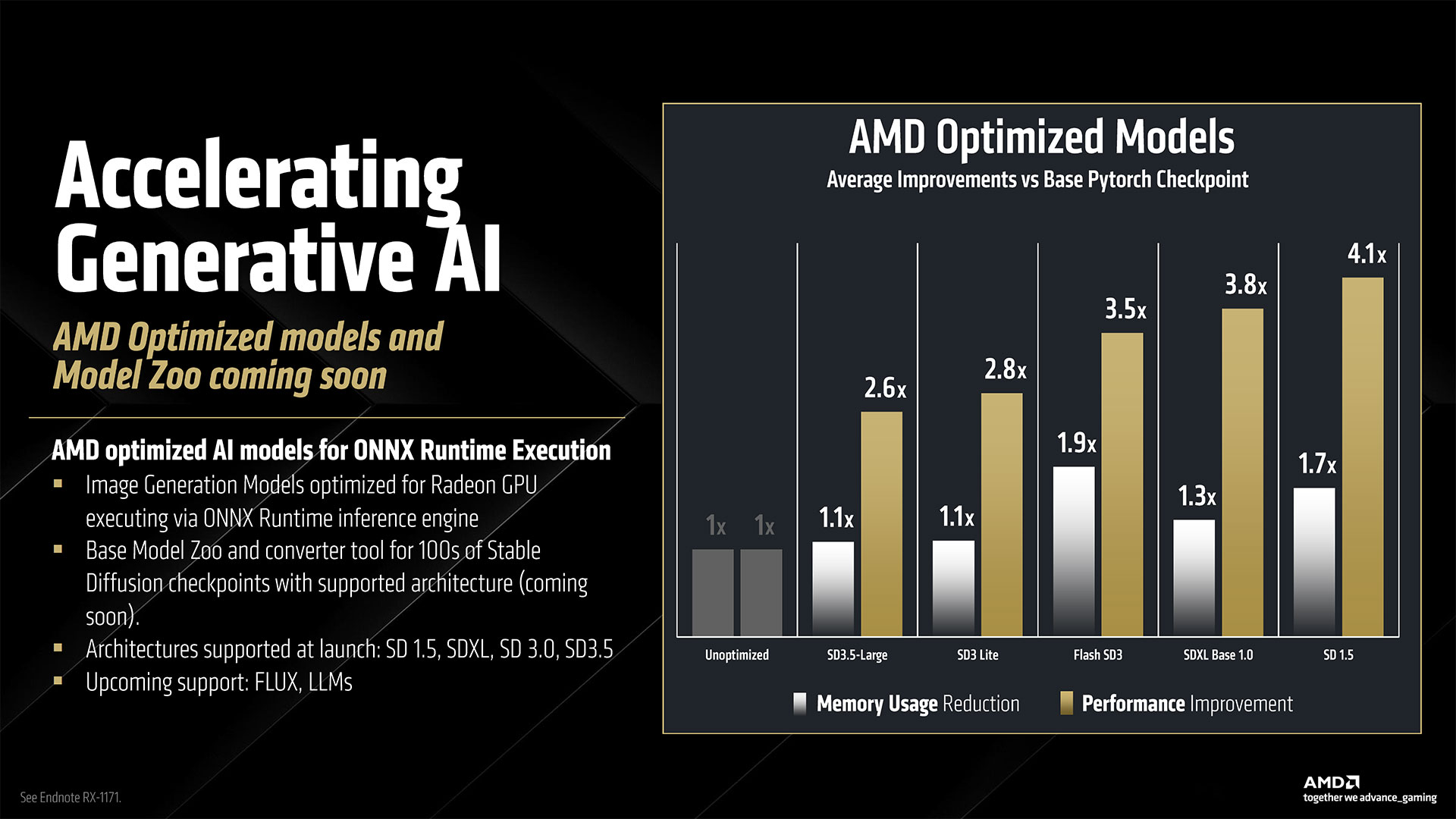
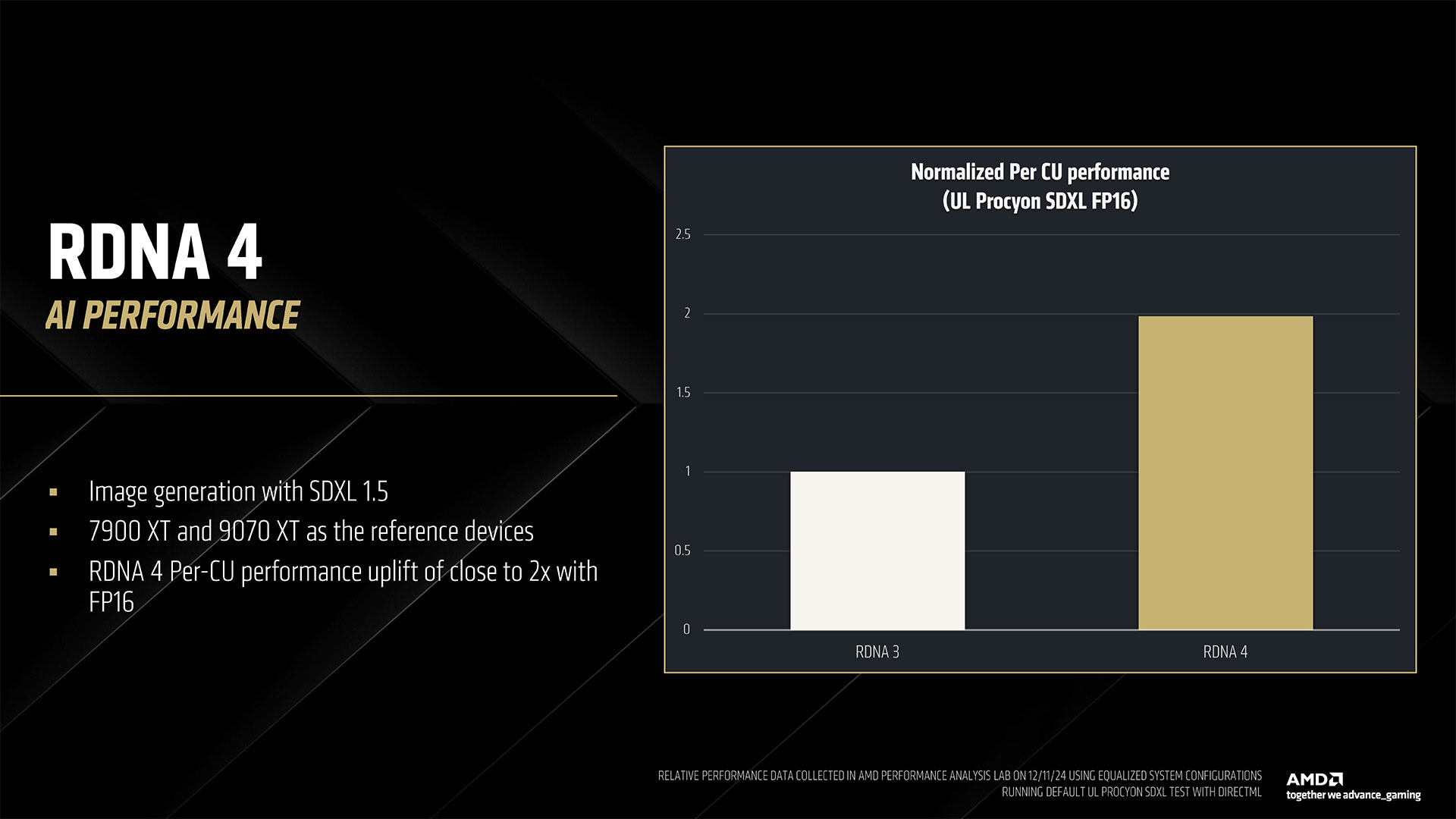
RDNA 3 CUs could do 512 FP16 operations per cycle, with no sparsity support, or 1024 INT4 operations per cycle. With RDNA 4, AMD doubles the baseline FP16 throughput for dense operations, doubles that again for sparse operations, and doubles that again for FP8 workloads — which are proving useful in the AI space. That’s up to 8X higher AI throughput for FP8 on RDNA 4 compared to FP16 on RDNA 3, and the INT4 throughput sees a similar up to 8X improvement.
AMD gave a real-world example of how this affects AI performance using Stable Diffusion XL. The RX 9070 XT with 64 CUs took on the RX 7900 XT with 84 CUs. That gives the older GPU a 31% advantage in compute units, but the 9070 XT ended up delivering very close to 2X the performance. That will prove very helpful for other AI and machine learning workloads, including ML-based upscaling and frame generation (see FSR 4 below).
Alongside these changes, AMD has reworked some of the cache and memory hierarchy with RDNA 4. It didn’t provide any clear details on what has changed, but it notes that this is the third generation of Infinity Cache. The capacity remains 64MB, the same as what was present on the 256-bit 7900 GRE and 7800 XT, but now the cache is again part of the monolithic chip, so it likely has better latencies and throughput.
RDNA 4 Other Architectural Improvements
RDNA 4 isn’t just about core architecture upgrades. Along with the above rasterization, ray tracing, and AI enhancements, AMD has also upgraded a few other areas. One of the big changes is with the media encoding hardware. Last time we checked video encoding performance and quality, AMD came in last place, clearly behind Nvidia and Intel. It looks like RDNA 4 will close the gap. AMD says it has improved H.264 (AVC) quality by up to 25%, H.265 (HEVC) by 11%, and improved the AV1 encoding efficiency. It also has better support for AV1 and VP9 decoding and reduced memory accesses. Besides the quality improvements, RDNA 4 adds a dual media engine. Nvidia did this with its Ada architecture, and AMD seems to be taking a similar approach. It likely doesn’t help all workloads equally, but AMD says it doubles the AV1 encoding throughput. Realistically, there’s only so far you can go with improving video encoding quality, particularly with hardware encoders. Intel and Nvidia are pretty comparable, but AMD was behind on quality while being ahead on performance with RDNA 3. It sounds like RDNA 4 will continue to be faster while offering similar quality to the competition, which is a good thing. Another change with RDNA 4 is that AMD has added hardware flip queue support, which offloads video frame scheduling to the GPU. While Nvidia discussed something similar for MFG (Multi Frame Generation), it sounds like AMD’s solution is focused on improving video playback by reducing CPU load, as opposed to being something to improve the scheduling of generated frames. Radeon Image Sharpening (RIS) has also been updated, to RIS2. This is a driver level sharpening solution that’s based on AMD’s CAS algorithm (Contrast Aware Sharpening), only now the quality is supposed to be better. It’s a single click toggle to apply RIS2 across all APIs.
Finally, RDNA 4 GPUs will support PCIe 5.0 interfaces. That doubles the throughput over the x16 link, though in practice most workloads likely won’t see much benefit. Gaming in particular doesn’t tend to need more than PCIe 3.0, or perhaps 4.0, when using a full x16 connection. However, AI and certain content creation tasks can benefit from the added bandwidth. Don’t be surprised if the future Navi 48 chips and possibly even the RX 9060 XT cut the interface down to x8 or even x4 widths.
(Image credit: AMD)
Sticking with GDDR6 VRAM
One thing that isn’t changing from RDNA 3 is the memory support. While Nvidia has moved all of the announced Blackwell RTX 50-series solutions to GDDR7 memory, AMD will continue to use GDDR6 memory, clocked at up to 20 Gbps. Coupled with a 256-bit interface on the 9070 XT and 9070 GPUs, that results in 640 GB/s of memory bandwidth. That’s the same VRAM capacity as the RX 7900 GRE and RX 7800 XT, and also the same as Nvidia’s RTX 5070 Ti and RTX 4070 Ti Super.
The 64MB Infinity Cache will improve the effective bandwidth, though AMD didn’t elect to provide any estimates of cache hit rates so far. The RX 7900 GRE and RX 7800 XT both had 64MB Infinity Caches, and AMD provided effective bandwidth rates that were about 4X the base memory bandwidth with those GPUs, so we’d anticipate the Navi 48 GPUs will see similar results.
It’s also possible that further improvements to the Infinity Cache have made it less critical for AMD to move to GDDR7 at present. Considering that Nvidia gets a 40% improvement in raw bandwidth from 28 Gbps GDDR7 compared to AMD’s 20 Gbps GDDR6, that might seem like a sizeable advantage. However, effective bandwidth after factoring in the large caches may not be all that different. Plus, there’s only so much bandwidth needed to drive a 64 CU GPU. Nvidia’s RTX 5070 Ti for example has 70 SMs (Streaming Multiprocessors), which are roughly analogous to AMD’s CUs, and the 5070 Ti has a 48MB L2 cache. Putting a larger 64MB L3 cache with fewer GPU processing clusters could reduce the need for higher memory speeds.
AMD continues to use 16Gb (2GB) GDDR6 modules, and we’re unaware of any companies currently pursuing 24Gb (3GB) capacities. That’s one area where GDDR7 support could prove beneficial for Nvidia in the future, though so far only the RTX 5090 Laptop GPU is using the higher capacity chips.
Monolithic GPUs, Built on TSMC N4P
One of the interesting changes with RDNA 4 is that AMD is, at least for now, ditching the GPU chiplets approach. It may come back to that in the future, but the Navi 48 and presumably the rumored Navi 44 will be monolithic chips. Along with that design choice, AMD is also upgrading from TSMC’s N5 process node used on RDNA 3 to the N4P node for RDNA 4. N4P provides for modest improvements in performance and efficiency compared to the N4 node, which in turn refines the base N5 node. Our understanding is that N4P may introduce some additional metal layers, and N4 used more EUV than N5. What’s not entirely clear is how N4P compares to 4N and 4NP — the “for Nvidia” variants that are used with Hopper, Ada, and Blackwell. It’s probably pretty similar in most respects, which means that AMD will be on node parity with Nvidia this round. But AMD isn’t really trying to take down Nvidia’s top GPUs. The lack of GDDR7 memory and the lack of a larger design prove this. The Navi 48 chip will house 53.9 billion transistors in a 356.5 mm^2 die. Nvidia’s GB203 used in the RTX 5080 and 5070 Ti contains 45.6 billion transistors in a 378 mm^2 die… which might suggest AMD actually has a superior process node and/or design. But we can’t really conclude that. While die sizes are pretty straightforward, transistor counts are not. They’re more of a mathematical estimate, and there are different ways of counting what constitutes a “transistor.” Perhaps AMD does have a denser design with more transistors, perhaps not. Ultimately, we’ll have to see how the various GPUs perform. One interesting side note here is that Navi 31, the top solution from the RDNA 3 family, had a 300 mm^2 GCD (Graphics Compute Die) with six 37.5 mm^2 MCDs (Memory Cache Dies). I wondered when AMD revealed the specs just how much it was actually saving by going the chiplet route. The GCD had 45.6 billion transistors, which means the overall transistor density — looking at the RDNA 3 GCD compared to the RDNA 4 monolithic design — is basically identical (152 MTrans/mm^2 on Navi 31 GCD compared to 151.2 Mtrans/mm^2 on Navi 48).
But let’s not get too carried away. It’s known that scaling on external interfaces — like the GDDR6 memory controllers — is quite poor with newer process nodes. Navi 31 used twelve 32-bit controllers while Navi 48 has eight 32-bit controllers. If AMD had attempted to make a 384-bit interface on a monolithic design, it would have certainly required a larger chip. Putting that on an older process node for the prior generation did make financial sense at the time, and may yet prove a smart approach for a future AMD product.
No “Made By AMD” Reference Cards
(Image credit: AMD)
If it wasn’t clear yet, AMD will not be making or selling its own reference model RX 9070 series graphics cards. Despite providing some slides of what appear to be MBA (Made By AMD) cards, these are merely graphical renders rather than photos of actual hardware. There were certainly prototype cards created during the design, testing, and validation process, but what those looked like isn’t really important. All of the RX 9070 series graphics cards will be made by AMD’s add-in board (AIB) partners. That means two things. First, we’ll see a lot of variation in final clock speeds and power draw, not to mention things like the number of fans and RGB lighting. But more importantly, it means AMD has a lot less say in the actual retail graphics card prices. Very likely AMD has a requirement that all of the AIBs have at least one model for each GPU that will be nominally priced at the stated MSRP. Beyond that, however, all bets are off. “Here’s our RX 9070 XT Red Herring for $599… and we sold all of those. Sorry! But you can pick up our Redder Herring OC model for $799!” We saw something like this with the RTX 5070 Ti cards, where there also isn’t a reference model from Nvidia.
Long-term, if there’s insufficient supply to meet the demand, most AIBs are going to produce higher tier models with a few minor extras and drastically inflated prices. If on the other hand the supply catches up to demand, then it’s easy enough to drop prices as needed.
FSR 4 and HYPR-RX
Image 1 of 28

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)
(Image credit: AMD)

(Image credit: AMD)
(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)
Besides the hardware, AMD has been working on a variety of feature improvements. The biggest one is undoubtedly FSR 4. The fourth iteration of AMD’s FidelityFX Super Resolution (FSR) algorithm, it will break with tradition in a couple of key ways.
First, FSR 4 will leverage the more potent AI accelerators in the RDNA 4 GPUs. At launch, it will require an RDNA 4 GPU. Down the road a few months, AMD may try back-porting the algorithm so that it can run on RDNA 3 and maybe even RDNA 2 GPUs… but it seems unlikely.
Instead, FSR 4 will basically co-exist with FSR 3.1, or rather, the non-AI upscaling will continue to be offered. It’s not entirely clear exactly how this will play out, but keeping everything unified under one name makes more sense. What we do know is that AMD plans to allow gamers to use the more potent FSR 4 algorithm on games that have FSR 3.1 support. Will that happen automatically or require a driver settings toggle? It seems like the latter but we’ll have to wait and see.
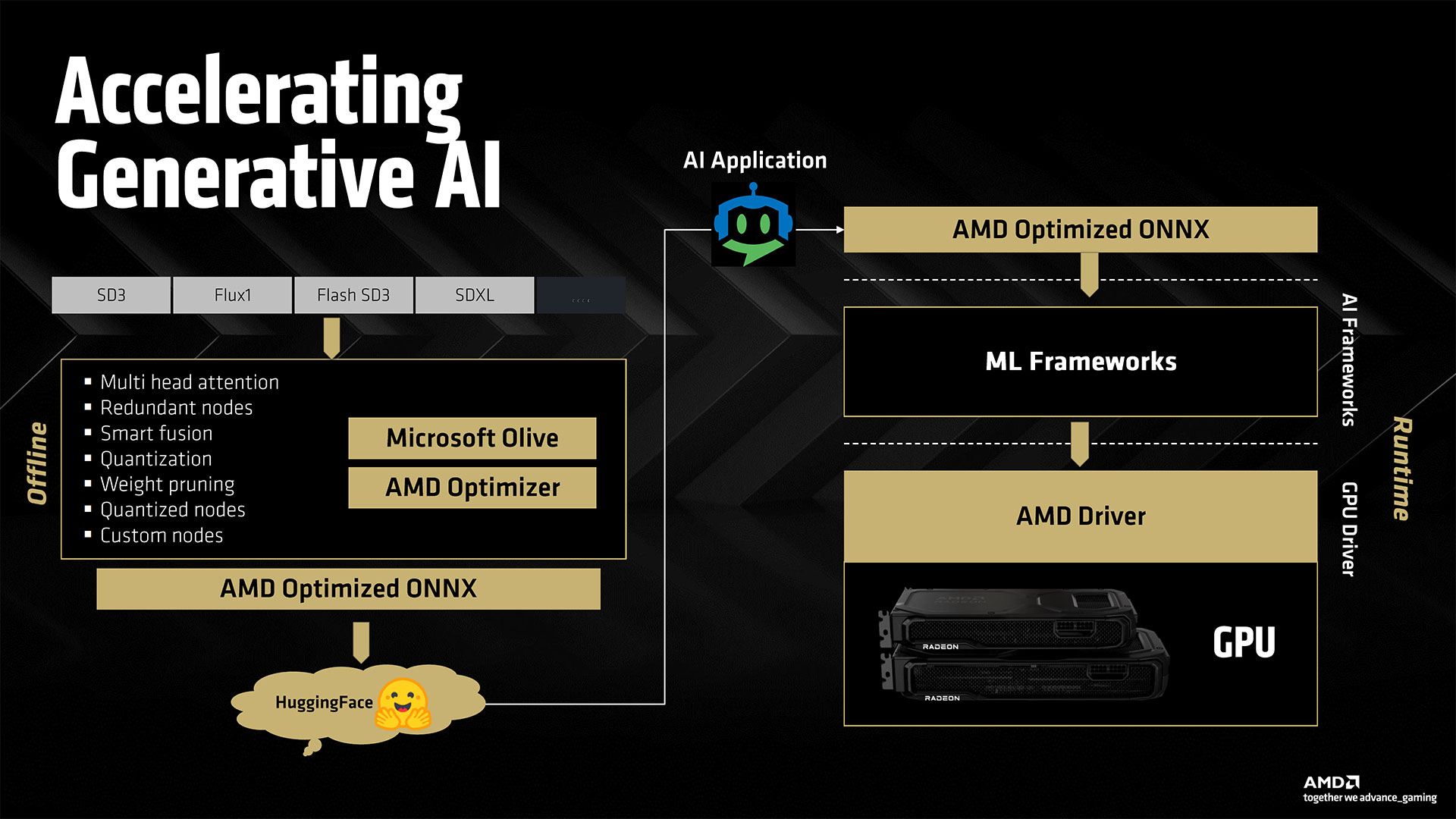
FSR 4 isn’t just for upscaling, either; it also has frame generation. From our understanding, both upscaling and framegen will use the AI accelerators of the RX 9000-series GPUs. AMD also says RDNA 4 is “neural rendering ready” without really going into further detail. Presumably that’s related to Microsoft‘s new Cooperative Vectors feature, which is something Nvidia also talked about with Blackwell.
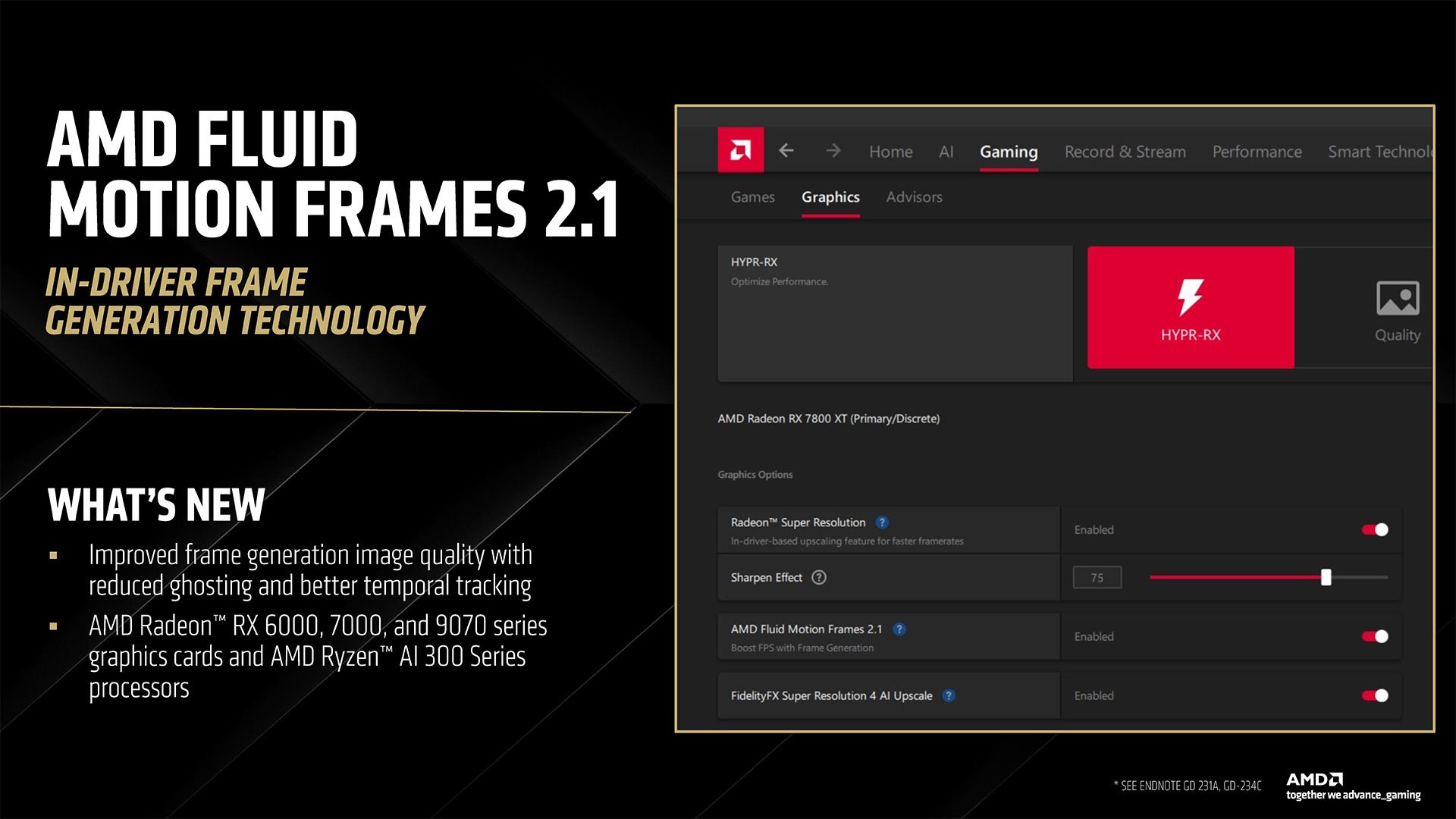
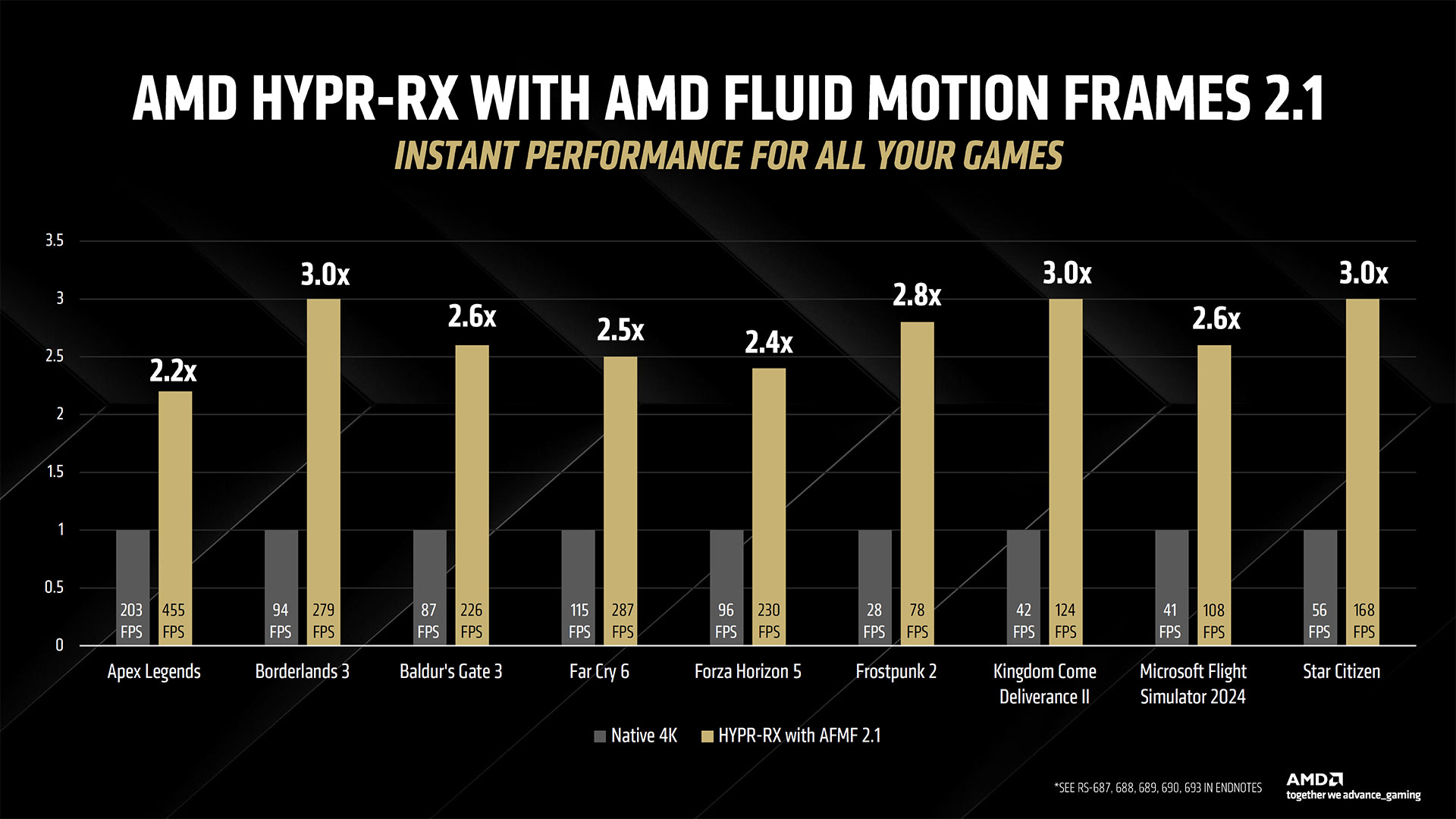
We’ve asked for additional details on how FSR 4 works, in terms of the computations. AMD hasn’t responded, but one slide does note that the RX 9070 XT offers “up to 779 TOPS AI Acceleration” while talking about FSR 4. Now, that’s either dense INT4 operations or sparse INT8 operations, as the 9070 XT hits double that figure for sparse INT4, but we don’t have a direct answer on whether the algorithms are using INT4 or INT8 yet. Either way, that’s a lot more theoretical compute than what you can get from prior generation AMD GPUs, which is why we don’t anticipate the AI upscaling and framegen models getting backported. We also asked if FSR 4 was using a transformers-based network or a convolutional neural network. DLSS 4 offers better image fidelity than DLSS 3 by using transformers, and AMD may have skipped the CNN approach since it’s late to the AI-powered upscaling and framegen party. However, we don’t have a direct answer yet. We do have some image quality comparisons from AMD, in the slides above, and FSR 4 definitely looks better than FSR 3.1. As with Nvidia’s use of performance mode upscaling with framegen, we don’t generally focus on the promised performance after all these extras. Framegen in particular is very heavy on marketing in our experience. It’s less problematic when you already have a high base framerate, but then it’s also less necessary when you’re already getting 100+ FPS. AMD says it will have over 30 games with FSR 4 enabled for the RX 9070 series launch, with 75+ games coming in 2025. AMD also talked about HYPR-RX, which combines a variety of driver-level performance boosting features and can be enabled with a single click. We’ve poked at it a bit in the past, and it can be useful in some cases, but we prefer sticking with apples to apples comparisons. If you’re just playing games, however, enabling HYPR-RX to apply all of the features including FSR/RSR, Anti-Lag, Radeon Boost, and AFMF 2 could be useful.
AMD also has a new AFMF 2.1 release that imprves the quality of the algorithm, reducing ghosting, improving fine features, and detecting and handling overlays better.
Drivers and Software
Image 1 of 27

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)
(Image credit: AMD)

(Image credit: AMD)
(Image credit: AMD)
(Image credit: AMD)

(Image credit: AMD)
(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)
(Image credit: AMD)

(Image credit: AMD)
(Image credit: AMD)
(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)

(Image credit: AMD)
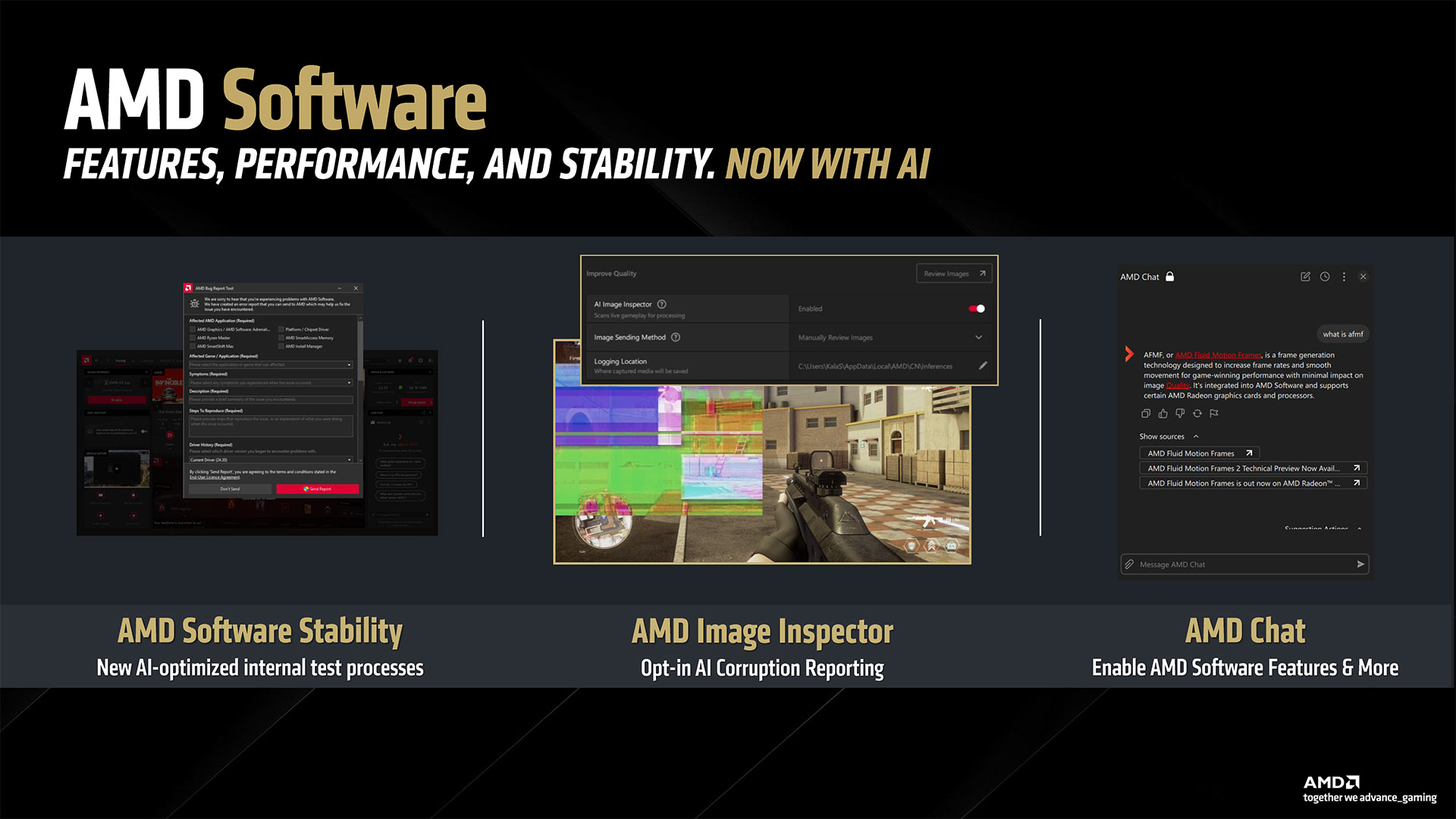
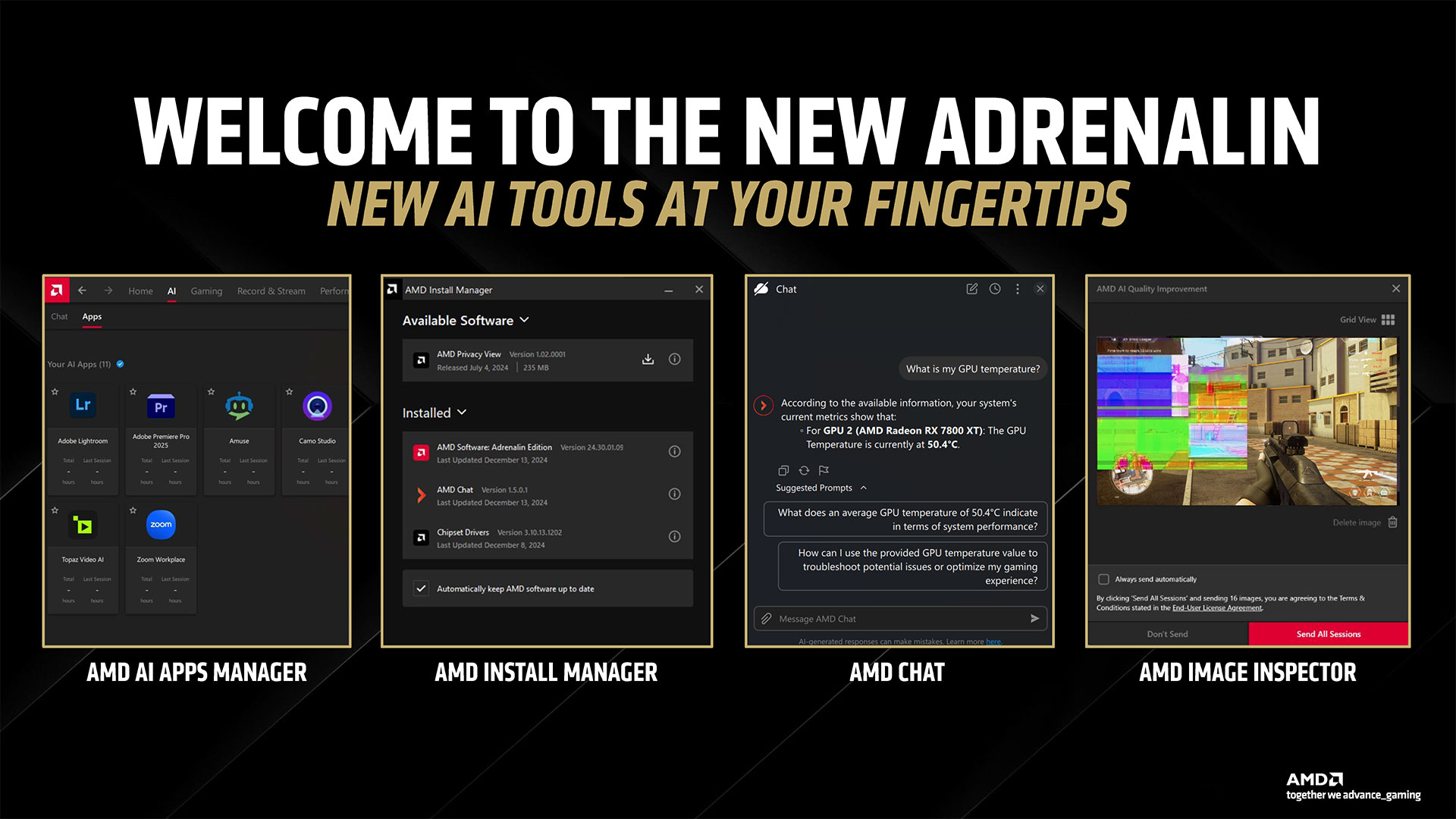
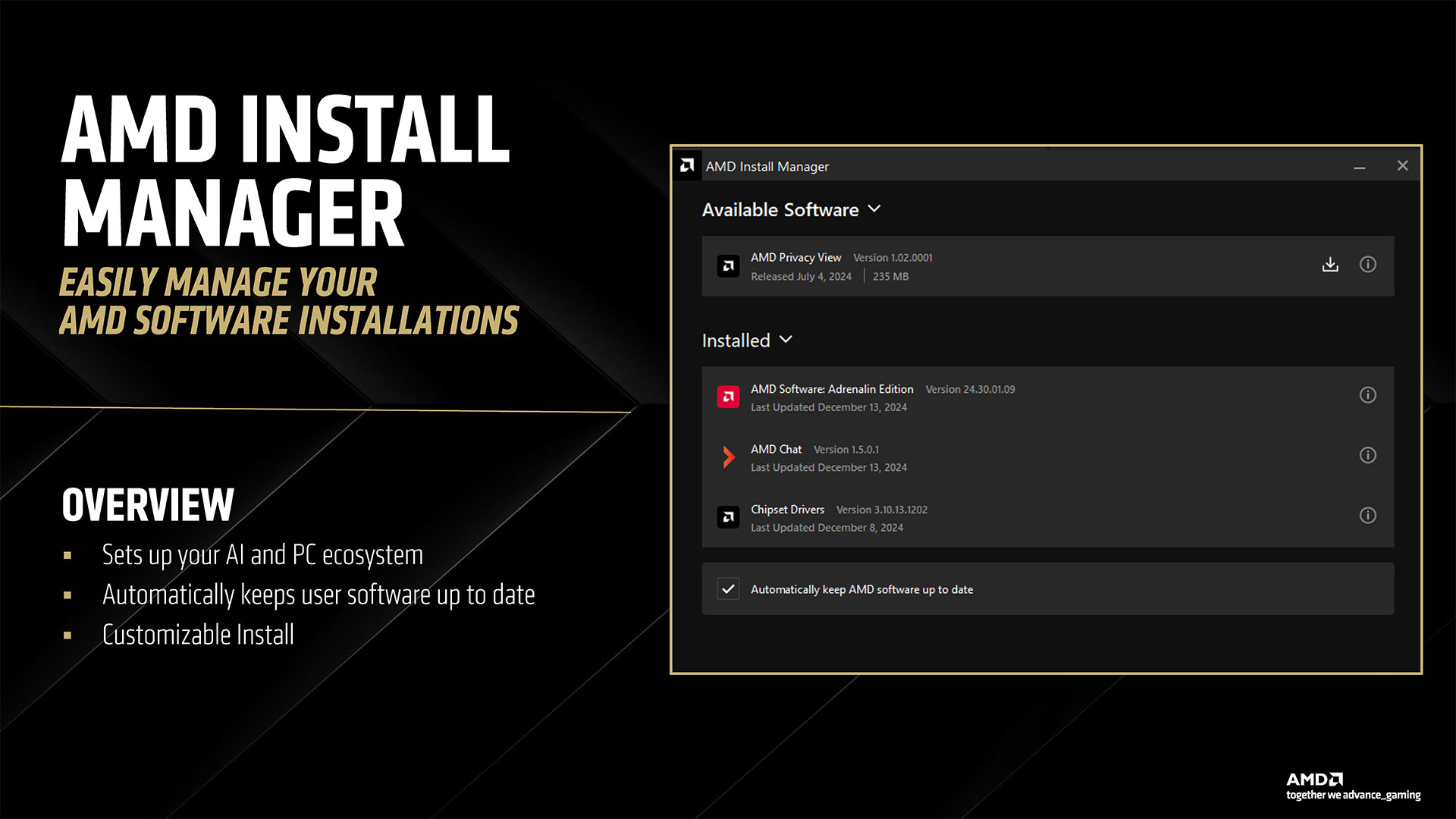
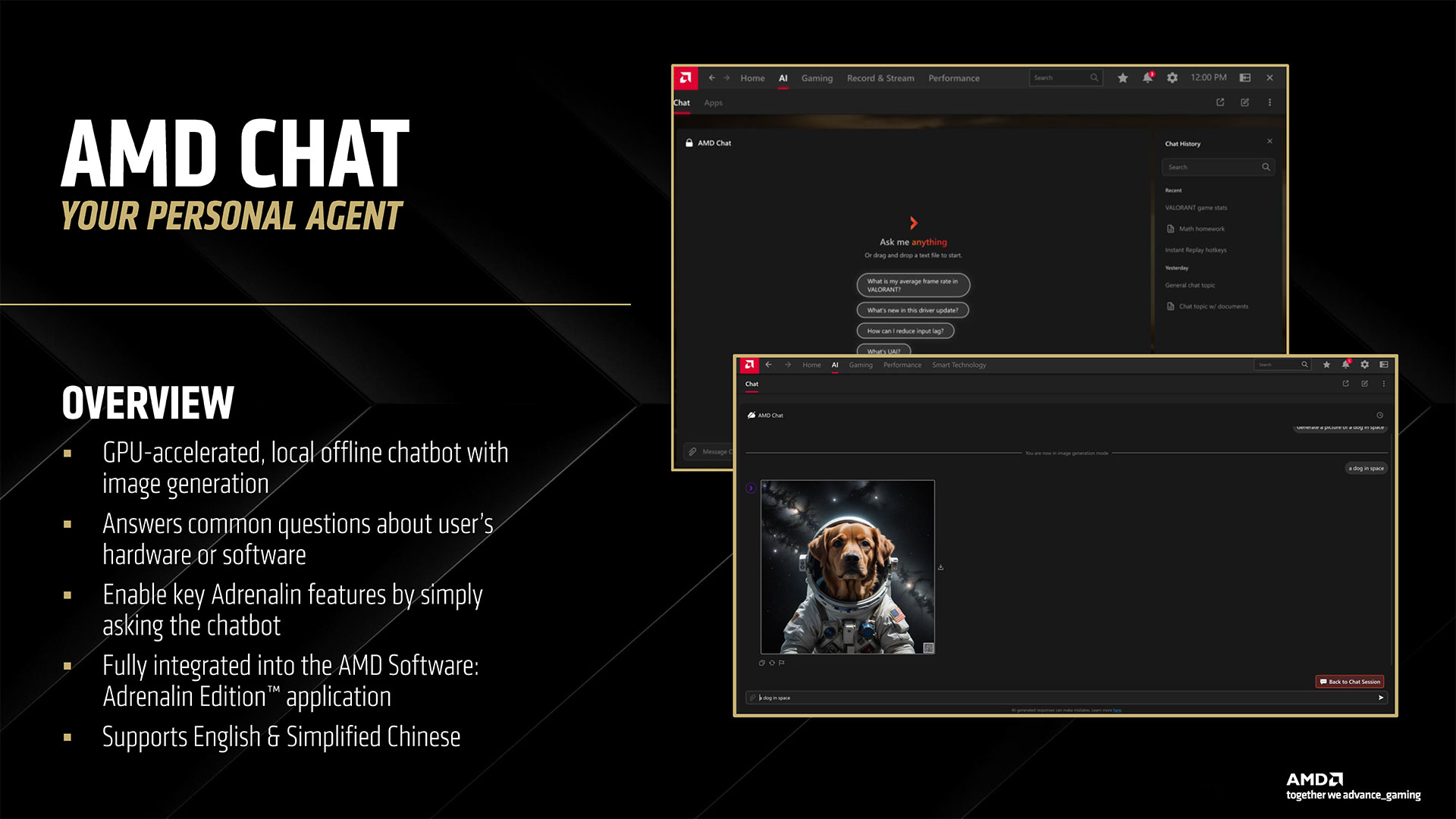
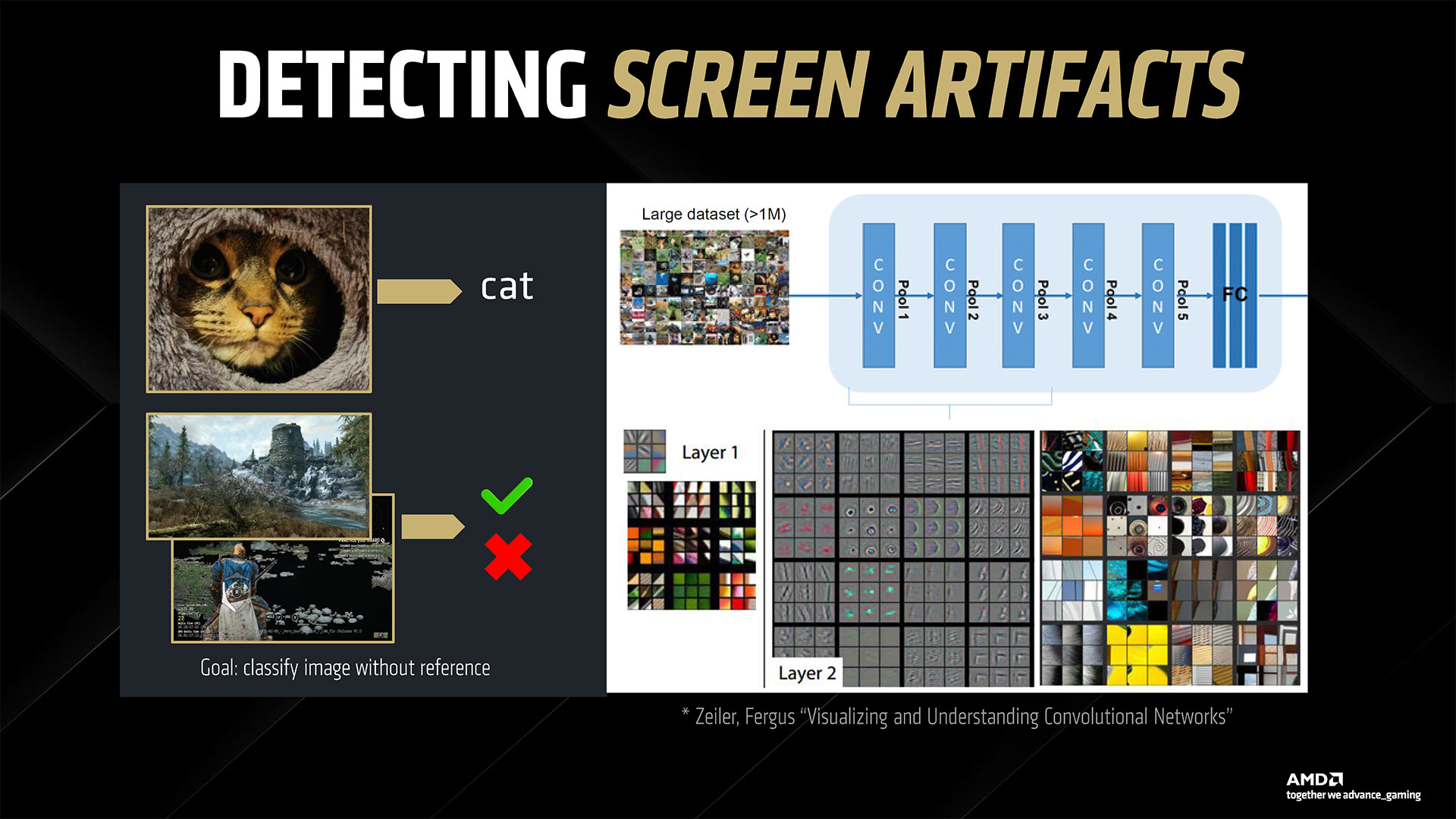
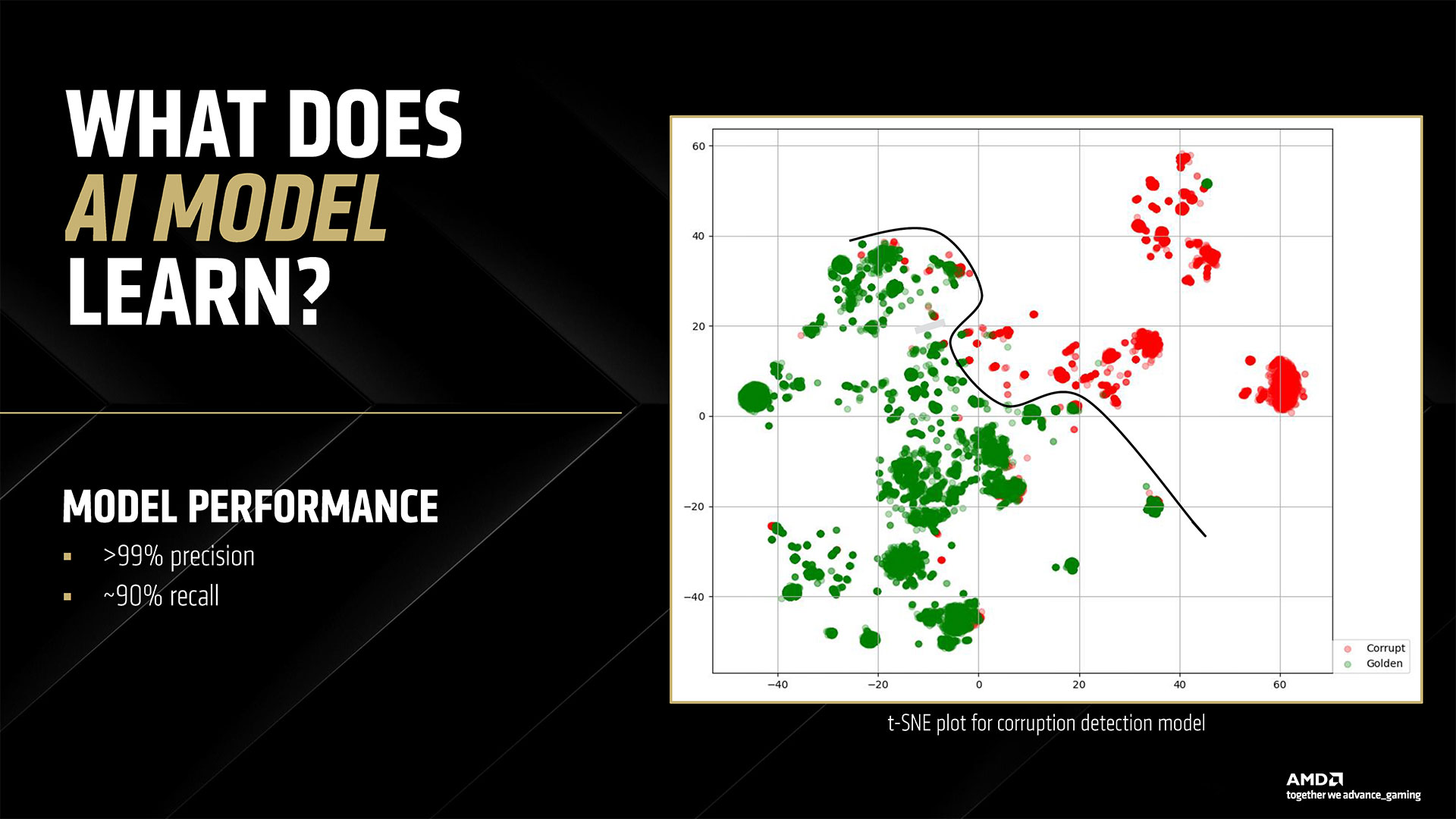
The last item AMD discussed is its new Adrenalin 25.3.1 drivers along with some new software. While most of the driver interface will be familiar to AMD GPU users, there are some new additions along with some behind the scenes changes. AI plays a role in both areas. We’ve already discussed FSR 4 upscaling and framegen, so let’s talk about the other AI uses. First, AMD is using AI to help find rendering errors and to detect instability and other issues. AMD claims its new 25.3.1 drivers will be perhaps the best and most stable drivers it has ever released, with fewer rendering errors. We’ll have to wait and see how that goes… Moving on, similar to Nvidia’s Chat RTX and other tools, AMD is providing some easy to access AI-powered features. These are all managed by a new AMD Install Manager that sits alongside the usual AMD Software in your system tray. Besides your GPU drivers, it can also detect if you have an AMD platform and keep your chipset drivers updated. And then there are some new extras: AMD Chat, AMD Image Inspector, and the AI Apps Manager (among others). AMD Chat is a chatbot designed to answer questions specifically about your PC hardware and GPU. You can ask it about GPU temperatures, performance, and more. It’s a hefty 25GB download, though, so you might not want to install if it you’re low on space — or if chatting with your PC isn’t something you plan on doing. The AI Apps Manager provides a list of software and utilities that can use AI that are installed or available to install. So if you have Adobe CC, some of those apps might show up. Or you can use it to install Amuse, AMD’s tuned AI image and video generation tool.
Finally, the Image Inspector is a feature to help with finding and reporting rendering errors and bugs. AMD is already using AI to help it find issues internally, and the Image Inspector is an opt-in feature that allows you to participate. Using spare GPU resources (so it won’t go crazy and use all your GPU power if you’re in a demanding game), it can automatically capture rendering errors and submit them to AMD, should you enable the feature. It sounds interesting, but we suspect there might be a performance hit still, even if it’s small.
The GPU landscape

(Image credit: Shutterstock)
Frankly, RDNA 4 feels like what AMD should have been doing with RDNA 3 rather than pursuing the abandoned-for-now GPU chiplets approach. AMD has finally decided to put serious effort into ray tracing hardware and AI in its consumer product line. We can understand why RDNA 2 was lacking in these areas — Nvidia’s GeForce RTX feature set probably caught the company off guard — but when RDNA 3 arrived in 2022, it really needed to do more and be more. What’s interesting is that all of these new hardware features haven’t caused a massive bloat in the die size. Navi 48 is 357 mm^2 on a 5nm-class node (N4P). Navi 31 was 300 mm^2 on a 5nm-class node (N5), with Infinity Fabric links to the external memory and cache chiplets. Rip out those links, rework the cores, and this was all possible several years ago. Which is obvious, since Nvidia already did that, but it felt like RDNA 3 doubled down on the “ray tracing and AI aren’t really that important” marketing and got left behind. RDNA 4 finally rights that misstep, or at least attempts to. Now we just need to see how the actual hardware performs in a variety of tasks.
AMD’s RDNA 4 GPUs will have to compete with Nvidia Blackwell RTX and Intel Arc Battlemage solutions. As we discussed already, supply and availability of all graphics cards has become quite poor of late. (Yes, that’s a sarcastic understatement.) Every recently launched GPU has sold out quickly, with many cards then selling at prices far above the original MSRP. It started with the Arc B580 and became especially painful with Nvidia’s Blackwell launches.
Things aren’t going to get better in the near term. The big issue is that there are a lot of companies competing for a limited supply of silicon manufacturing. TSMC only has the ability to process so many wafers in a month. Right now, AMD, Apple, Intel, and Nvidia are all using TSMC for various chips, and there are plenty of other companies as well — Broadcom, Facebook, Google, Amazon… the list can get quite large.
Even if a company pays for a certain number of wafers in a given month, what to do with those wafers is still up for debate. Just looking at the main PC companies, AMD could make RDNA 4 GPUs on TSMC’s N4P node, sure. Or it could make Zen 5 CPU chiplets for both Ryzen and EPYC CPUs, CDNA 3 data center GPUs (MI300X), other Ryzen APU designs for laptops and handhelds, or the future CDNA 4 GPUs that are likely coming this year. Nvidia has Grace CPUs, Hopper and Blackwell data center GPUs, NVLink processors, Ada Lovelace previous generation GPUs, and the new Blackwell RTX GPUs that are all using variants of TSMC’s 5nm-class nodes. And Intel has leveraged TSMC for all or part of its Arrow Lake, Lunar Lake, and Battlemage product lines.
Nvidia made record profits last year of $130 billion, primarily driven by AI. Its consumer gaming division only accounted for $11.35 billion, 8.7% of the total. And going forward, Nvidia will likely invest even more heavily in data center GPUs. That will eat up a lot of wafers, needless to say, and gaming will have to compete for its share.
The good news is that more manufacturing capacity is coming online. A lot of that will likely go to create more AI processors, but the more capacity that exists, the more likely it is for other, less profitable chips — like consumer GPUs — to get made. And maybe AMD and Intel will try to grow their gaming GPU divisions while Nvidia is otherwise occupied. Or maybe Nvidia will treat gaming as a passion project that started the company and so it will try to ensure at least a reasonable number of chips get made. Maybe, maybe…
Whatever happens, what’s clear right now is that, as long as AI continues to grow as an industry, gaming GPUs are now a lower priority item for most of the biggest players in the graphics space. Let’s hope that, like cyptocurrency mining, this turns out to be just a passing phase. But we wouldn’t bet the farm on that.
